

인공신경망 설계 시 고려사항
-
Network topology
네트워크의 모양 (feed forward, feed backward)
-
Activation function
출력의 형태
-
Objectives
분류? 회귀?
Loss function, Error로 나타낼 수 있음
-
Optimizers
weight update
-
Generalization
Overfitting 방지
2. activation function
출력의 형태 결정
1. one-hot vector

여러 값 중 하나의 값만 출력
ex_ 숫자 식별
2. softmax function

해당 출력이 나올 확률로 표현
3. objective function

기타 목적함수
- Mean absolute error / mae
- Mean absolute percentage error / mape
- Mean squared logarithmic error / msle
- Hinge = max(0,1− t∙f(x))
- Squared hinge
- Sparse categorical cross entropy
- Kullback leibler divergence / kld
- Poisson: mean of (predictions - targets * log(predictions))
- Cosine proximity: the opposite (negative) of the mean cosine proximity between predictions and targets.
문제의 유형
회기 (regression)
출력이 연속값을 갖는 함수를 대상으로 훈련 data를 잘 재현하는 함수를 찾는 것
Linear activation function + MSE Objective function
ex_ 매출액 추정, 생산 속도에 따른 불량률 추정
Binary classification
출력을 0,1 두 가지로 판단 (출력의 형태가 one-hot vector)
d = 0 or 1

d=1이면 확률은

0이면

확률들의 합을 가장 크게 만드는 (오류를 작게 만드는) w를 구하는 것이 목적

목적함수 (Loss function)
곱셈을 많이하면 underflow가 생기므로 log 붙여주기
최대화문제 => 최소화문제
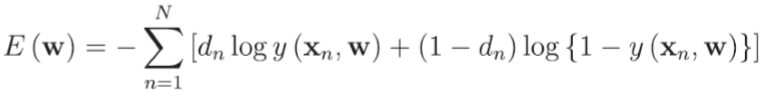
Logistic activation function + Binary cross Entropy Objective function
multi-class classification
각 클래스에 해당하는 확률을 출력
softmax activation function + categorical cross entropy Objective function

n번째 testcase의 k번째 출력에 대한 확률
binary를 k개의 출력에 대해 모두 나타낸 방식
ex_ 숫자 필기 인식
4. Optimizers
: weight update 방법
-
Stochastic gradient descent
이 아래로는 SGD의 응용들임
-
Momentum
-
Learning rate decay
-
Rmsprop
-
Adagrad
-
Adadelta
-
Adam
-
Adamax
-
Nadam
-
Nesterov
weight 업데이트
-
oneline
학습 시 weight를 샘플 하나마다 Error에 대해 분석해서 update하는 방식
-
batch or deterministic gradient methods
모든 샘플에 대해 계산되는 error function을 사용
모든 input에 대해서 weight의 변화 값을 구해서 평균을 사용
시간이 많이 걸림
-
minibatch or minibatch stochastic(확률론적) methods
샘플의 일부만을 이용해서 파라미터 update
보통 50-100개
Stochastic gradient descent

m개의 샘플을 가지고 training 시킴
=> 기울기의 평균을 택해서
=> learning rate를 곱하고 weight update
장점
-
비슷한 데이터를 쓸 경우 (중복성이 있을 때) 학습이 빠름
-
local minimum에 빠질 확률이 줄어듬
매번 mini-batch를 랜덤으로 뽑기 때문
-
update가 작은 크기로 진행
학습의 경과 관찰 용이
-
Online 학습
데이터가 계속 갱신될 때, 수집과 최적화 동시 진행 용이
원리
기울기 벡터가 정확하게 계산되지 않으므로 극소값에 빠지지 않을 수 있음
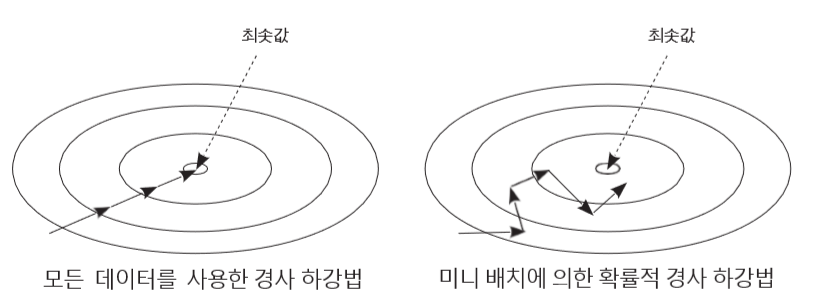
단점
weight의 기울기가 그대로 적용되어 이동하기 때문에 진동으로 학습에 많은 시간이 걸릴 수 있음
=> 해결방법 : 볼에 공을 담아두었다고 물리적으로 생각해보기
=> Momentum
Momentum
가속도 개념을 적용해서 이전 weight의 변화를 어느정도 유지함
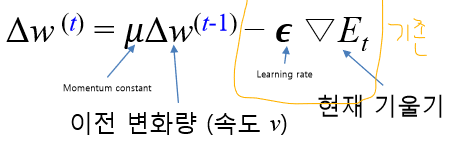
변화량은 이전 변화량에 가속도 상수를 곱한 후, 현재 변화량을 빼준 것

SGD에 대비해서 Momentum으로 수정된 모습

Nesterov momentum
momentum의 응용버전.
기존 Momentum 방법과의 차이점은 기울기를 미리 업데이트 한다는 것이다.

weight에 이미 이동한 정도(av)만큼을 이동했다고 가정한 상태로 learning 진행
이 부분은 Momentum과 다름
learning 후 av만큼을 또 더해서 weight update
이 부분은 Momentum과 같음
기존 Momentum 방법에서 correction factor를 더한 방식이라고 일컬어짐
correction factor: equation을 성립시키기 위해 곱해지는 요인


https://ruder.io/optimizing-gradient-descent/
An overview of gradient descent optimization algorithms
Gradient descent is the preferred way to optimize neural networks and many other machine learning algorithms but is often used as a black box. This post explores how many of the most popular gradient-based optimization algorithms such as Momentum, Adagrad,
ruder.io
AdaGrad
지금까지 업데이트한 기울기를 저장해두었다가, 많이 나온 기울기 성분을 줄이기
드물게 나타나는 기울기 성분을 더 중시 => learning rate를 크게

t'=1 ~t
처음 시작 부터 현재까지
g^2(t',i)
wi가 이동한 기울기 벡터 (기울기 방향)
자주 나오는 기울기 벡터들은 큰 수가 되어 learning rate를 나누게 되므로 learning rate가 작아짐

문제
목표점을 상실할 수 있음
Rmsprop(Root Mean Square Propagation)
Adagrad에서 아래 그림에 표시된 식만 바뀜

기울기의 빈도를 따지는 것이 아니라, 과거 현재를 따져서 최근의 기울기, 과거의 기울기를 얼마나 고려할 것인지 판단하는 방법
r은 과거 기울기, g는 현재 기울기 벡터이므로 ρ(로우)가 얼마나 과거를 기억할 것인지를 의미함
문제
시간이 흐를 수록 update 양이 작아짐
The Adam algorithm
Adam = Adagrad + momentum

너무 어렵다 ... 나중에 다시 공부
*친 부분 : 처음에는 learning이 빠르게 하기 위해서 첫 시도 시 g에 곱해지는 상수를 없애줌
Adam = Rmsprop + momentum
장점
결정해주는 상수 값에 따라서 성능이 많이 달라지지 않음
5. Generalization
: training 에 사용되지 않은 data (Test set)에 대한 성능
Overfitting (주어진 data에 대해서만 과도하게 적합) 될 수도 있음
Overfitting
이유
weight (model parameter) 에 비해서 학습 data가 너무 적은 경우에 발생
weight 수와 학습 data 수는 비례해야함
똑똑한 인공지능을 위해서는 많은 data가 필요함
해결
-
weight의 수를 줄이기 (성능 떨어뜨리기)
Regularization
-
training data의 수를 늘리기
수업시간에 나왔던 질문
그렇다면 data가 부족한 상황에서는 test set에 data를 부여하는 것보다 training set에 data를 몰아주는게 더 의미있지 않을까?
N-fold 라는 방법으로 data set을 N개로 나누어서 train/valid/test를 계속 바꿔가며 test하는 방법이 있음
Regularization
Overfitting을 방지하기 위해 목적함수(loss function)에 complexity penalty(regularization 목적함수) 추가
에러도 줄이고 regularization도 해야함
-
L2 Regularization
J(w) = MSE + λwTw
wTw : w vector의 내적
앞에 곱해지는 상수는 w가 적을 수록 선호한다는 것을 뜻함
많을 수록 목적함수 값이 높아짐 => 만족하기 어려움
-
L1 Regularization
J(w) = MSE + λ||w||1
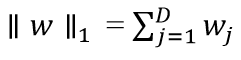
(∥ 𝑤 ∥1 = σ𝑗=1 𝐷 𝑤𝑗 )
그냥 더해서 사용하면 음수가 나와서 제곱으로 사용하는 것이 나음
=> L2를 사용하는 것이 좋음
'컴퓨터과학 (CS) > AI' 카테고리의 다른 글
| 인공지능 정리 [본론7] :: 깊어진 인공신경망의 문제점? (0) | 2020.02.29 |
|---|---|
| 인공지능 정리 [본론6] :: deep neural network에서의 backpropagation (0) | 2020.02.10 |
| 인공지능 정리 [부록] :: theta가 필요한 이유 (0) | 2020.02.10 |
| 인공지능 정리 [본론5] :: 신경망의 원리 (0) | 2020.02.09 |
| 인공지능 정리 [부록] :: Restricted Boltzmann Machine (RBM) (0) | 2020.02.08 |
Comment